Overview
A Mirror Pipeline defines flow of data fromsources -> transforms -> sinks. It is configured in a yaml file which adheres to Goldsky’s pipeline schema.
The core logic of the pipeline is defined in sources, transforms and sinks attributes.
sourcesrepresent origin of the data into the pipeline.transformsrepresent data transformation/filter logic to be applied to either a source and/or transform in the pipeline.sinksrepresent destination for the source and/or transform data out of the pipeline.
source and transform has a unique name which is referenceable in other transform and/or sink, determining dataflow within the pipeline.
While the pipeline is configured in yaml, goldsky pipeline CLI commands are used to take actions on the pipeline such as: start, stop, get, delete, monitor etc.
Below is an example pipeline configuration which sources from base.logs Goldsky dataset, filters the data using sql and sinks to a postgresql table:
base-logs.yaml
Keys for sources, transforms and sinks are user provided values. In the above example, the source reference name
base.logs matches the actual dataset name. This is the convention that you’ll typically see across examples and autogenerated configurations. However, you can use a custom name as the key.Development workflow
Similar to the software development workflow ofedit -> compile -> run, there’s an implict iterative workflow of configure -> apply -> monitor for developing pipelines.
configure: Create/edit the configuration yaml file.apply: Apply the configuration aka run the pipeline.monitor: Monitor how the pipeline behaves. This will help create insights that’ll generate ideas for the first step.
Understanding runtime lifecycle
Thestatus attribute represents the desired status of the pipeline and is provided by the user. Applicable values are:
ACTIVEmeans the user wants to start the pipeline.INACTIVEmeans the user wants to stop the pipeline.PAUSEDmeans the user wants to save-progress made by the pipeline so far and stop it.
ACTIVE has a runtime status as well. Runtime represents the execution of the pipeline. Applicable runtime status values are:
STARTINGmeans the pipeline is being setup.RUNNINGmeans the pipeline has been setup and is processing records.FAILINGmeans the pipeline has encountered errors that prevents it from running successfully.TERMINATEDmeans the pipeline has failed and the execution has been terminated.
Successful lifecycle
In this scenario the pipeline is succesfully setup and processing data without encountering any issues. We consider the pipeline to be in a healthy state which translates into the following statuses:- Desired
statusin the pipeline configuration isACTIVE - Runtime Status goes from
STARTINGtoRUNNING
base-logs.yaml
goldsky pipeline apply base-logs.yaml --status ACTIVE or goldsky pipeline start base-logs.yaml
ACTIVE. We can confirm this using goldsky pipeline list:
goldsky pipeline monitor base-logs-pipeline command:
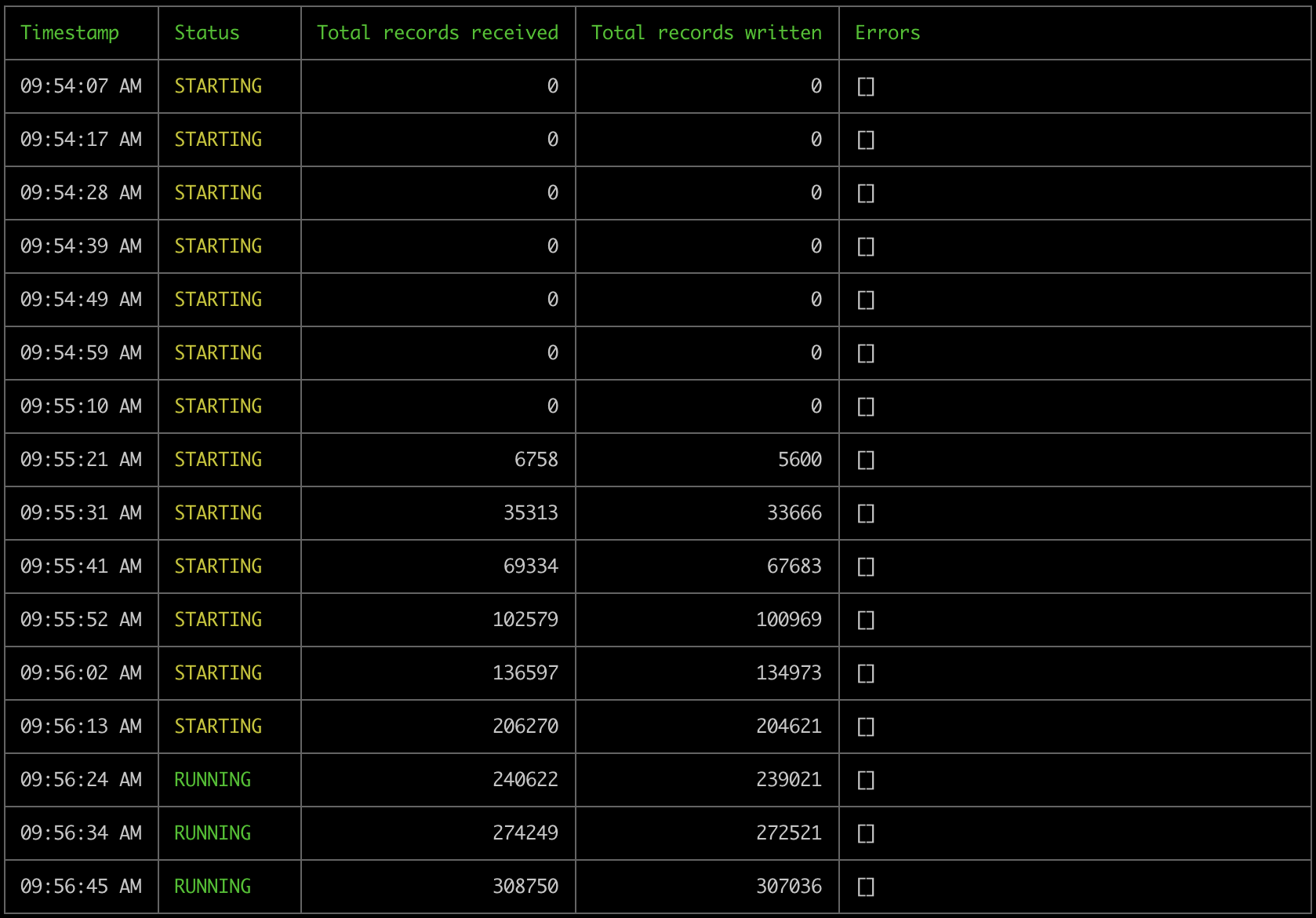
STARTING status and becomes RUNNING as it starts processing data successfully into our Postgres sink.
This pipeline will start processing the historical data of the source dataset, reach its edge and continue streaming data in real time until we either stop it or it encounters error(s) that interrupts it’s execution.
Unsuccessful lifecycle
Let’s now consider the scenario where the pipeline encounters errors during its lifetime and ends up failing. There can be multitude of reasons for a pipeline to encounter errors such as:- secrets not being correctly configured
- sink availability issues
- policy rules on the sink preventing the pipeline from writing records
- resource size incompatiblity
- and many more
RUNNING runtime status.
A Pipeline can be in an ACTIVE desired status but a TERMINATED runtime status in scenarios that lead to terminal failure.
Let’s see an example where we’ll use the same configuration as above but set a secret_name that does not exist.
bad-base-logs.yaml
goldsky pipeline apply bad-base-logs.yaml.
goldsky pipeline monitor bad-base-logs-pipeline we see:
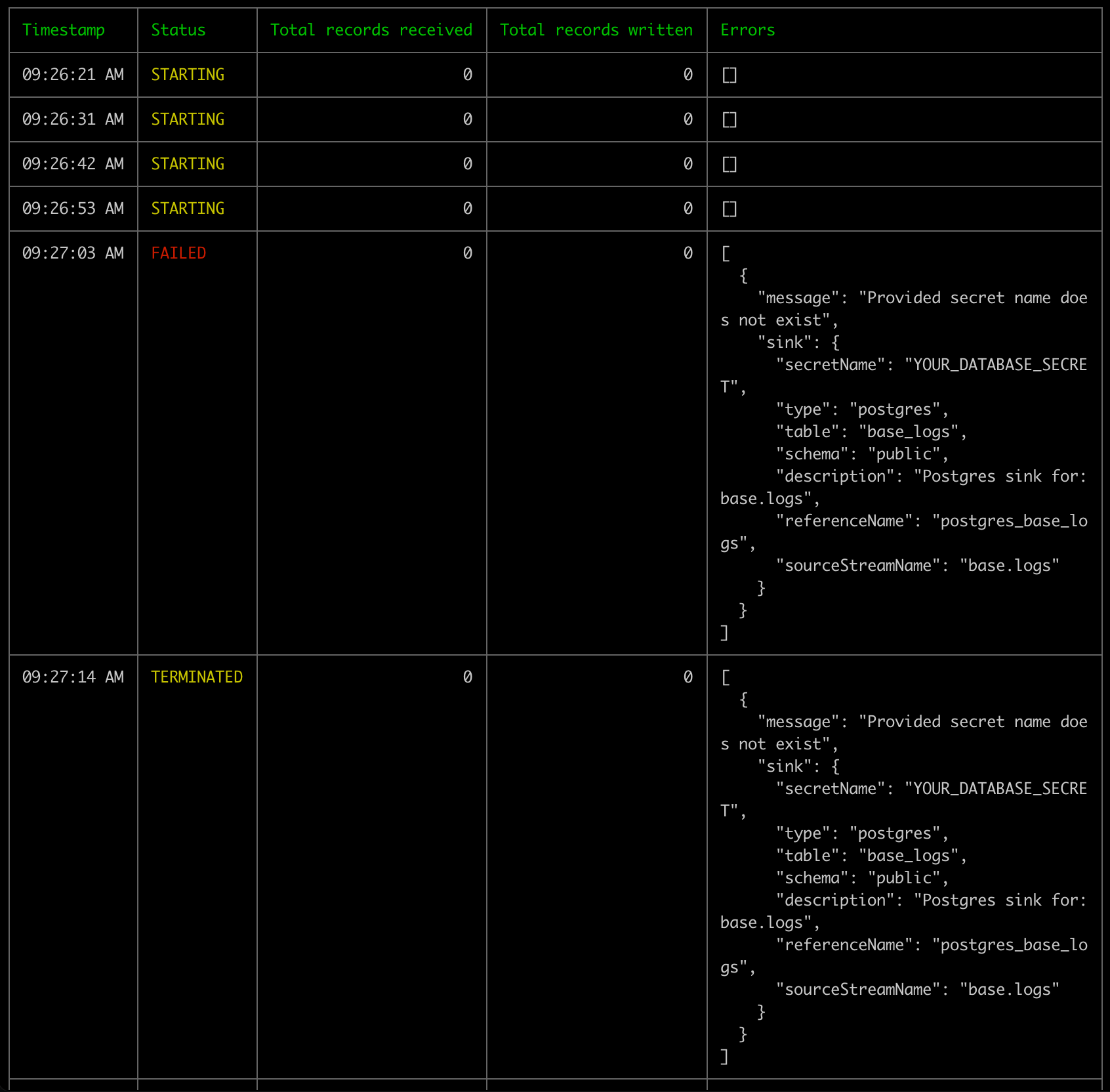
ACTIVE even though the pipeline runtime status is TERMINATED
Runtime visibility
Pipeline runtime visibility is an important part of the pipeline development workflow. Mirror pipelines expose:- Runtime status and error messages
- Logs emitted by the pipeline
- Metrics on
Records received, which counts all the records the pipeline has received from source(s) and,Records writtenwhich counts all records the pipeline has written to sink(s). - Email notifications
- Pipeline dashboard at
https://app.goldsky.com/dashboard/pipelines/stream/<pipeline_name>/<version> goldsky pipeline monitor <name_or_path_to_config_file>CLI command
Email notifications
If a pipeline fails terminally the project members will get notified via an email.
Error handling
There are two broad categories of errors. Pipeline configuration schema error This means the schema of the pipeline configuration is not valid. These errors are usually caught before pipeline execution. Some possible scenarios:- a required attribute is missing
- transform SQL has syntax errors
- pipeline name is invalid
- credentails stored in the secret are incorrect or do not have needed access privilages
- sink availability issues
- poison-pill record that breaks the business logic in the transforms
resource_sizelimitation
Resource sizing
resource_size represents the compute (vCPUs and RAM) available to the pipeline. There are several options for pipeline sizes: s, m, l, xl, xxl. This attribute influences pricing as well.
Resource sizing depends on a few different factors such as:
- number of sources, transforms, sinks
- expected amount of data to be processed.
- transform sql involves joining multiple sources and/or transforms
- A
smallresource size is usually enough in most use case: it can handle full backfill of small chain datasets and write to speeds of up to 300K records per second. For pipelines using subgraphs as source it can reliably handle up to 8 subgraphs. - Larger resource sizes are usually needed when backfilling large chains or when doing large JOINS (example: JOIN between accounts and transactions datasets in Solana)
- It’s recommended to always follow a defensive approach: start small and scale up if needed.
Snapshots
A Pipeline snapshot captures a point-in-time state of aRUNNING pipeline allowing users to resume from it in the future.
It can be useful in various scenarios:
- evolving your
RUNNINGpipeline (eg: adding a new source, sink) without losing progress made so far. - recover from new bug introductions where the user fix the bug and resume from an earlier snapshot to reprocess data.
When are snapshots taken?
- When updating a
RUNNINGpipeline, a snapshot is created before applying the update. This is to ensure that there’s an up-to-date snapshot in case the update introduces issues. - When pausing a pipeline.
- Automatically on regular intervals. For
RUNNINGpipelines in healthy state, automatic snapshots are taken every 4 hours to ensure minimal data loss in case of errors. - Users can request snapshot creation via the following CLI command:
goldsky pipeline snapshot create <name_or_path_to_config>goldsky pipeline apply <name_or_path_to_config> --from-snapshot newgoldsky pipeline apply <name_or_path_to_config> --save-progress true(CLI version <11.0.0)
- Users can list all snapshots in a pipeline via the following CLI command:
goldsky pipeline snapshot list <name_or_path_to_config>
How long does it take to create a snapshot
The amount of time it takes for a snapshot to be created depends largly on two factors. First, the amount of state accumulated during pipeline execution. Second, how fast records are being processed end-end in the pipeline. In case of a long running snapshot that was triggered as part of an update to the pipeline, any future updates are blocked until snapshot is completed. Users do have an option to cancel the update request. There is a scenario where the the pipeline was healthy at the time of starting the snapshot however, became unhealthy later preventing snapshot creation. Here, the pipeline will attempt to recover however, may need user intervention that involves restarting from last successful snapshot.Scenarios and Snapshot Behavior
Happy Scenario:- Suppose a pipeline is at 50% progress, and an automatic snapshot is taken.
- The pipeline then progresses to 60% and is in a healthy state. If you pause the pipeline at this point, a new snapshot is taken.
- You can later start the pipeline from the 60% snapshot, ensuring continuity from the last known healthy state.
- If the pipeline reaches 50%, and an automatic snapshot is taken.
- It then progresses to 60% but enters a bad state. Attempting to pause the pipeline in this state will fail.
- If you restart the pipeline, it will resume from the last successful snapshot at 50%, there was no snapshot created at 60%