- Goldsky Flow: With a guided web experience in the dashboard
- CLI: interactively or by providing a pipeline configuration
Goldsky Flow
Flow allows you to deploy pipelines by simply dragging and dropping its component into a canvas. You can open up Flow by going to the Pipelines page on the dashboard and clicking on theNew pipeline button.
- Select the Data Source
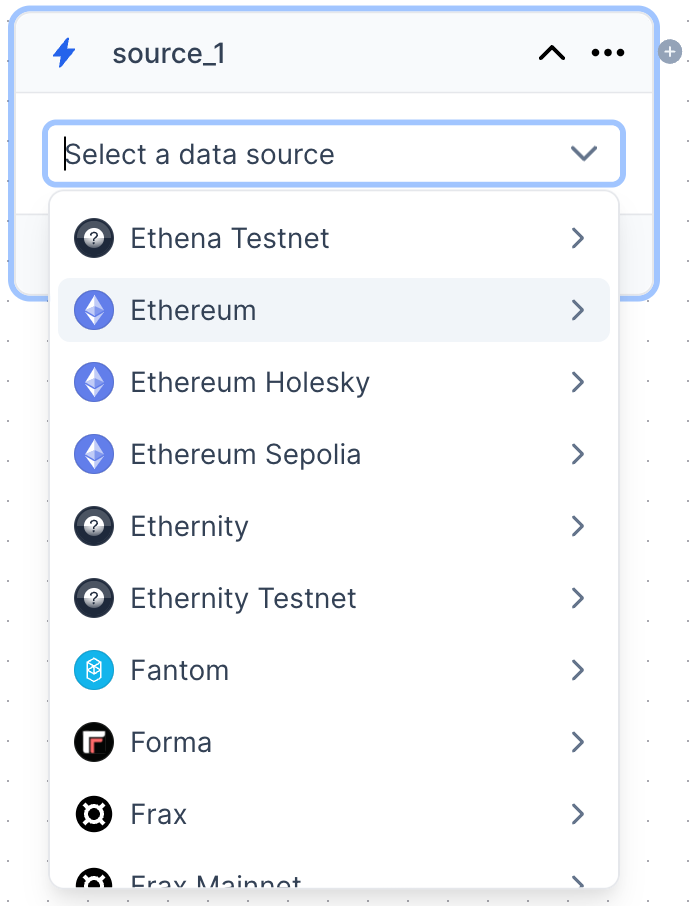
Data Source card onto the canvas. Once you do that, you’ll to need select the chain you are interested in. We currently support 100+ chains. For this example we are going to choose Ethereum.
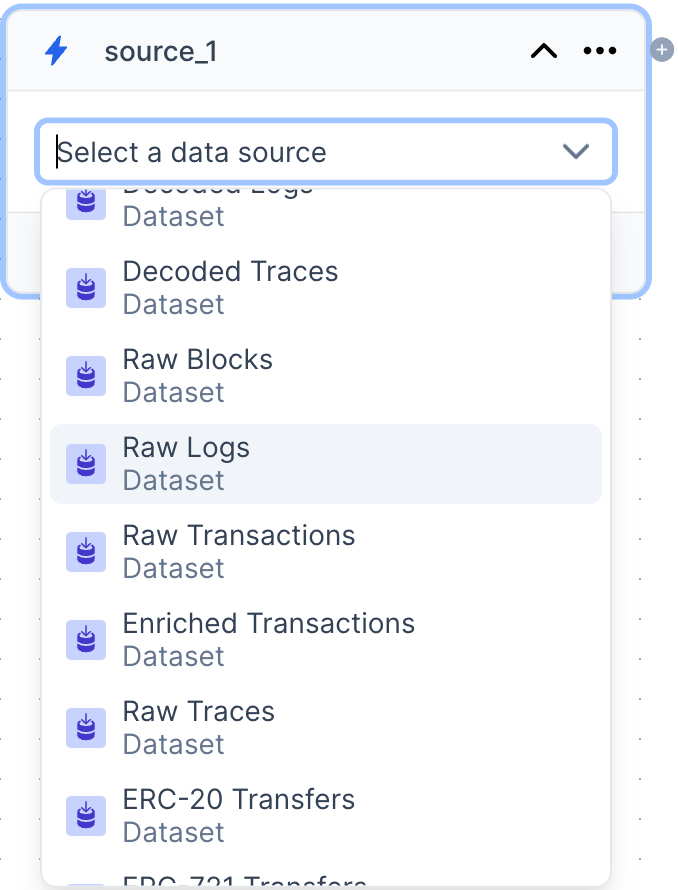
- Onchain datasets: these are Direct Indexing datasets representing both raw data (e.g. Raw Blocks) as well as curated datasets (e.g. ERC-20 Transfers)
- Subgraphs: this can be community subgraphs or existing subgraphs in your project for the choosen network
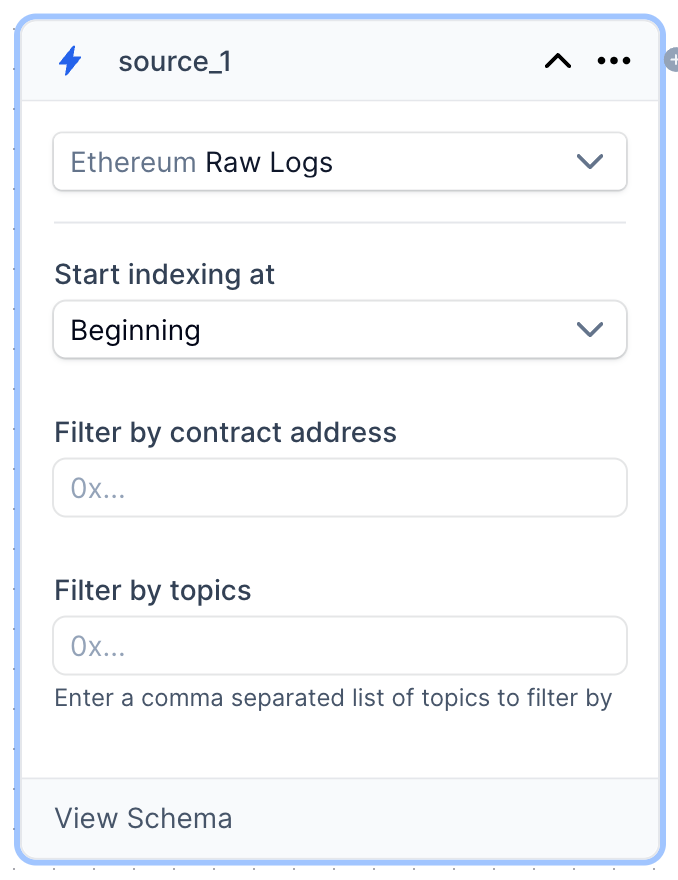
Raw Logs.
Onchain Datasets you can configure:
Start indexing at: here you can define whether you want to do a full backfill (Beginning) or read from edge (Current)Filter by contract address: optional contract address (in lowercase) to filter fromFilter by topics: optional list of topics (in lowercase) to filter from, separated by commas.View Schema: view the data schema to get a better idea of the shape of the data as well as see some sample records.
- (Optional) Select a Transform
+ button at the top right edge of the Data Source card and you’ll have the option to add a Transform or a Sink.
Custom SQL.
Query field of the card to bring up the SQL editor.
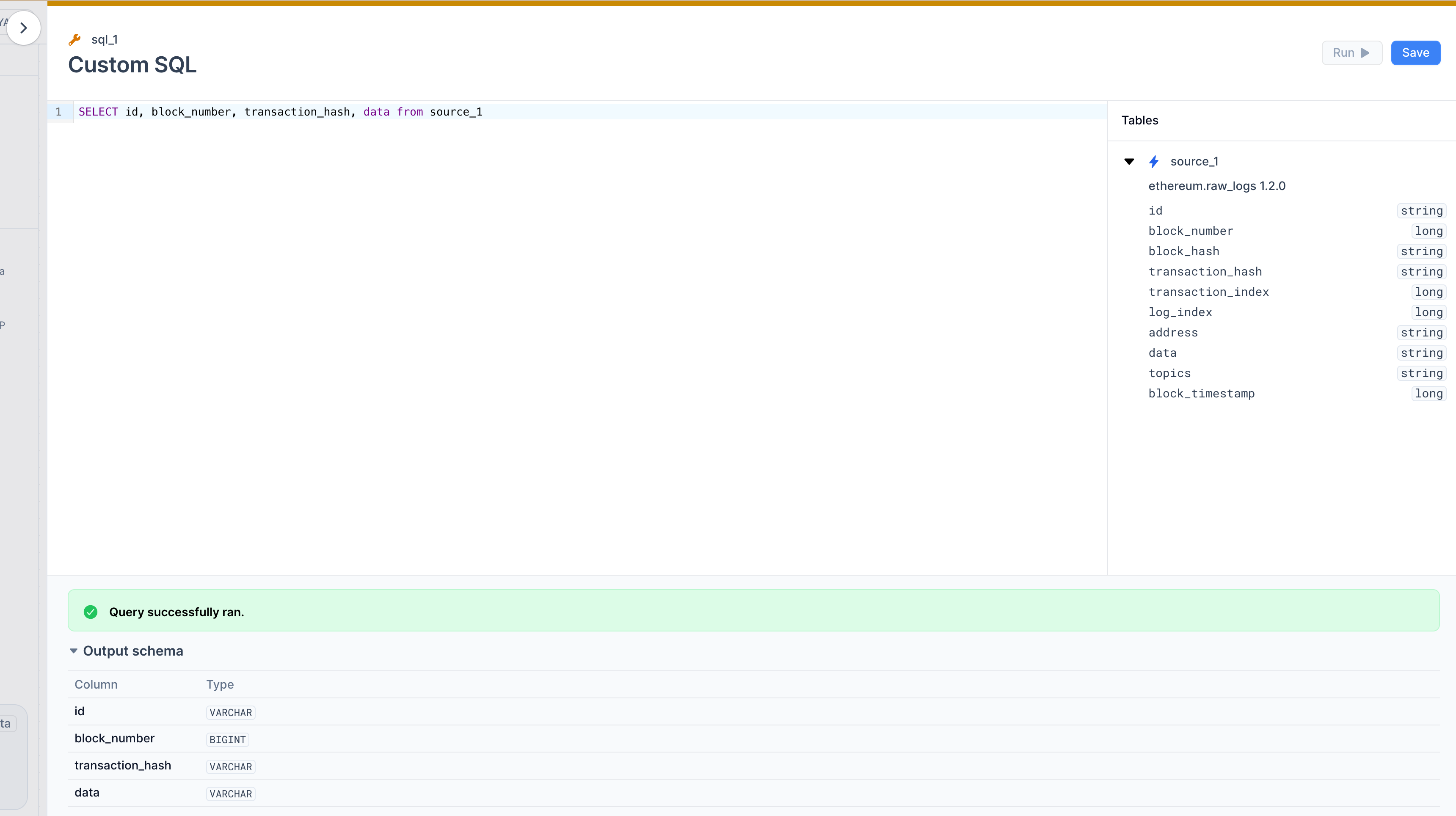
SELECT id, block_number, transaction_hash, data FROM source_1
If you click on the Run button on the top right corner you’ll see a preview of the final shape of the data. Once satisfied with the results in your Transforms, press Save to add it to the pipeline.
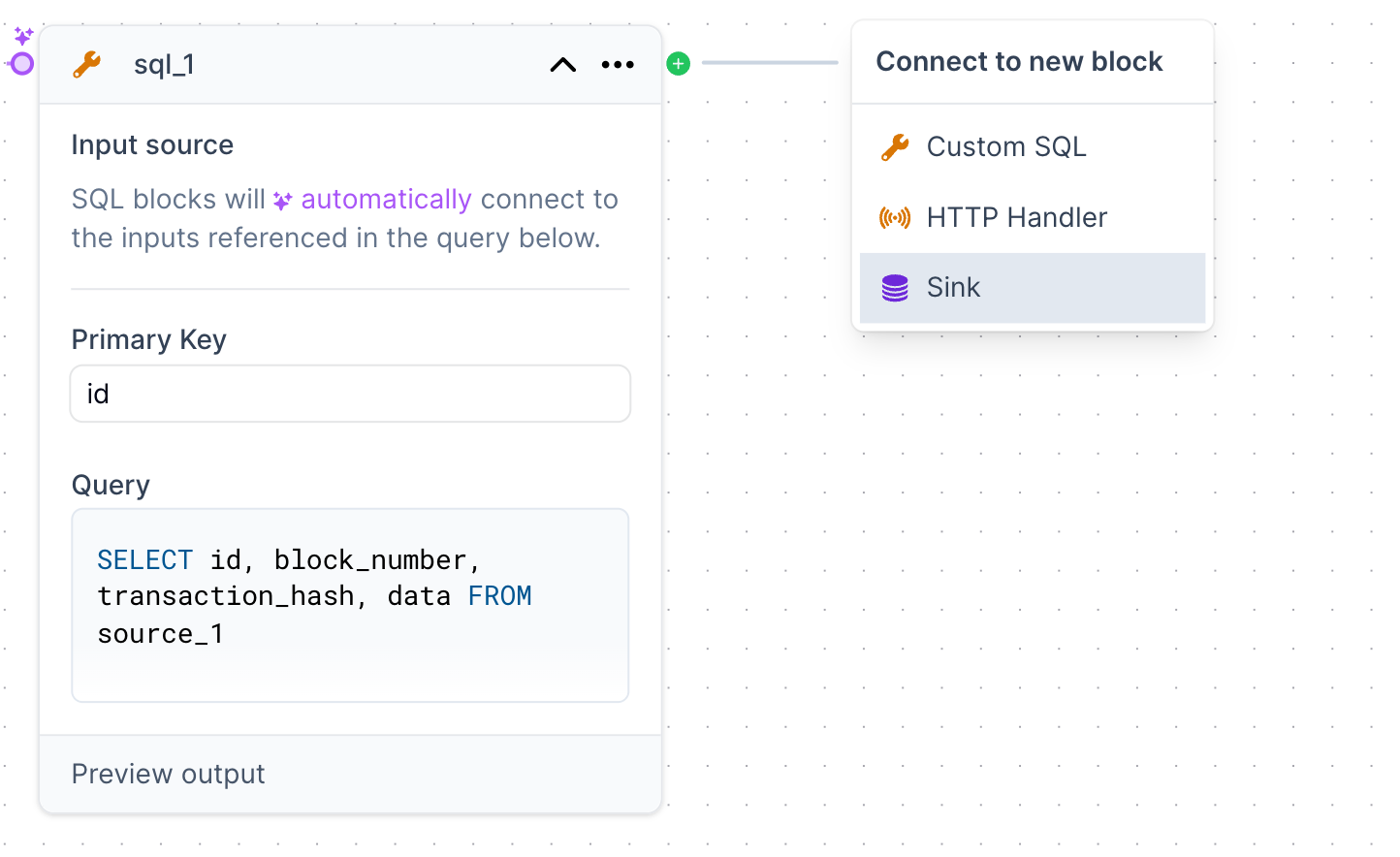
- Select the Sink
+ button at the top right edge of the Transform Card and select a Sink.
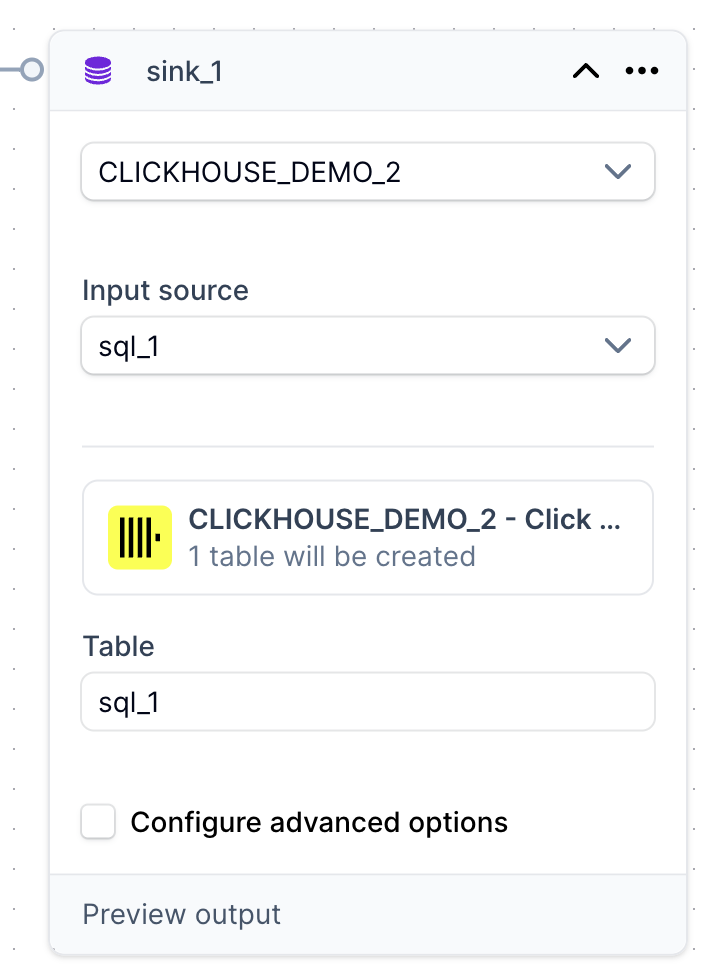
Preview Output button to see the what the final shape of the data will be; this is a very convenient utility
in cases where you might have multiple sources and transforms in your pipeline and you want to iterate on its logic without having to redeploy the actual pipeline every time.
- Confirm and deploy
ethereum-raw-logs
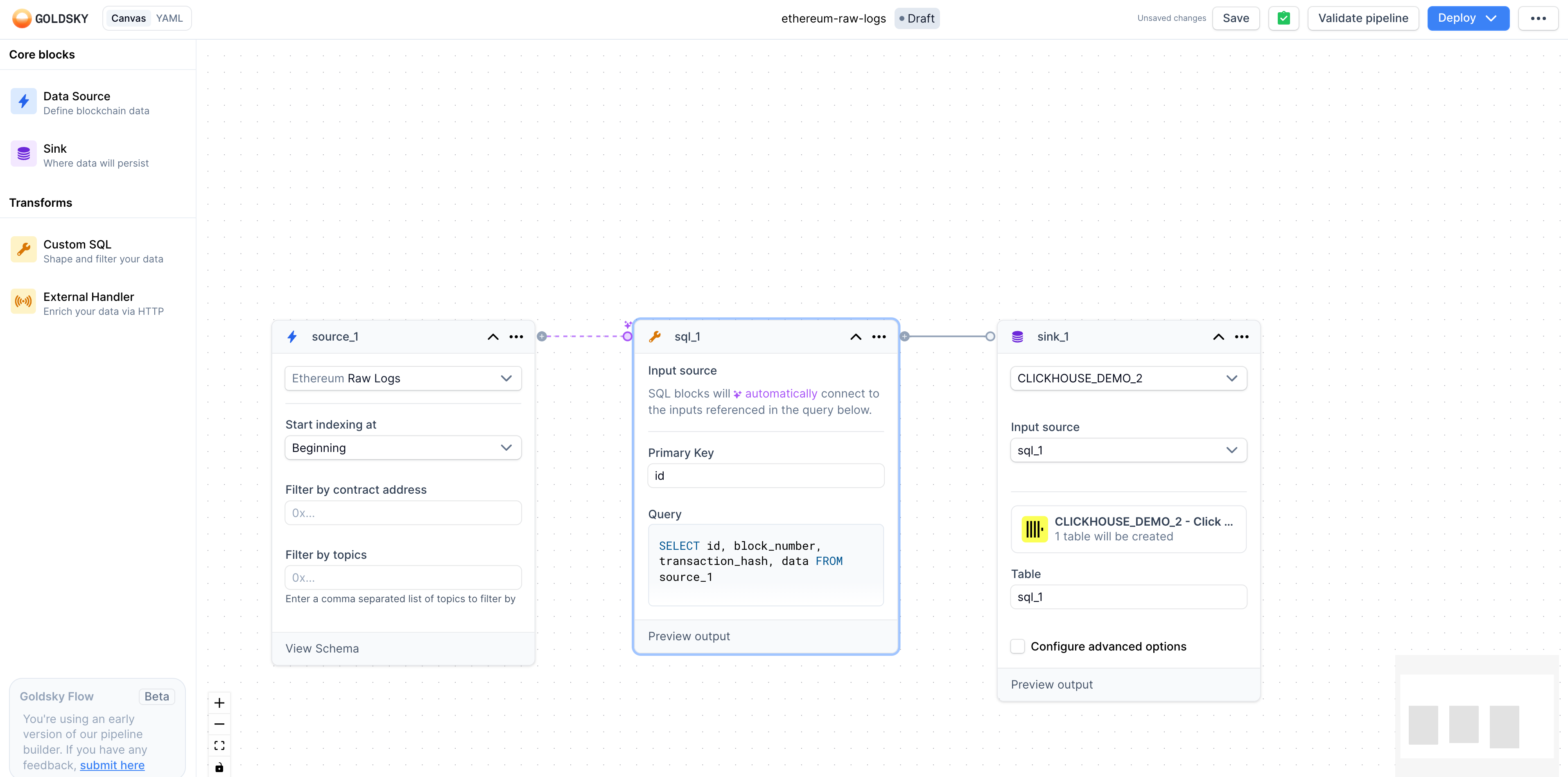
Up to this point, your canvas should look similar to this:
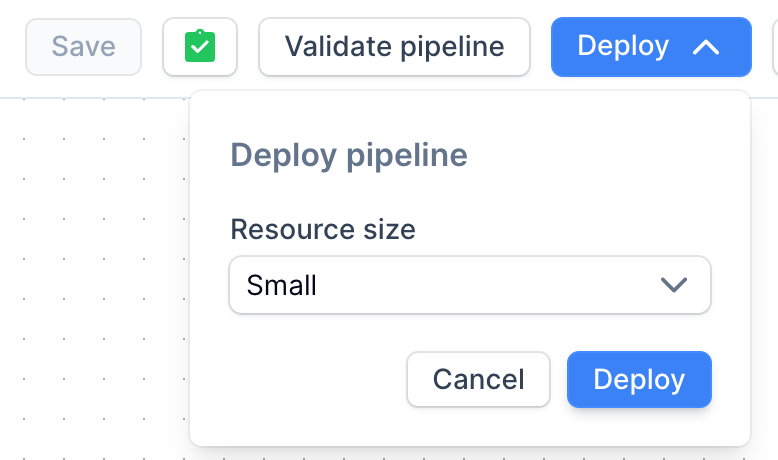
Deploy button on the top right corner and specify the resource size; for this example you can choose the default Small.
Update Pipeline button on the top right corner of the page and it will take you back onto the Flow canvas so you can do any updates on it.

- Pipelines are formally defined using configuration files in YAML. Goldsky Flow abstract that complexity for us so that we can just
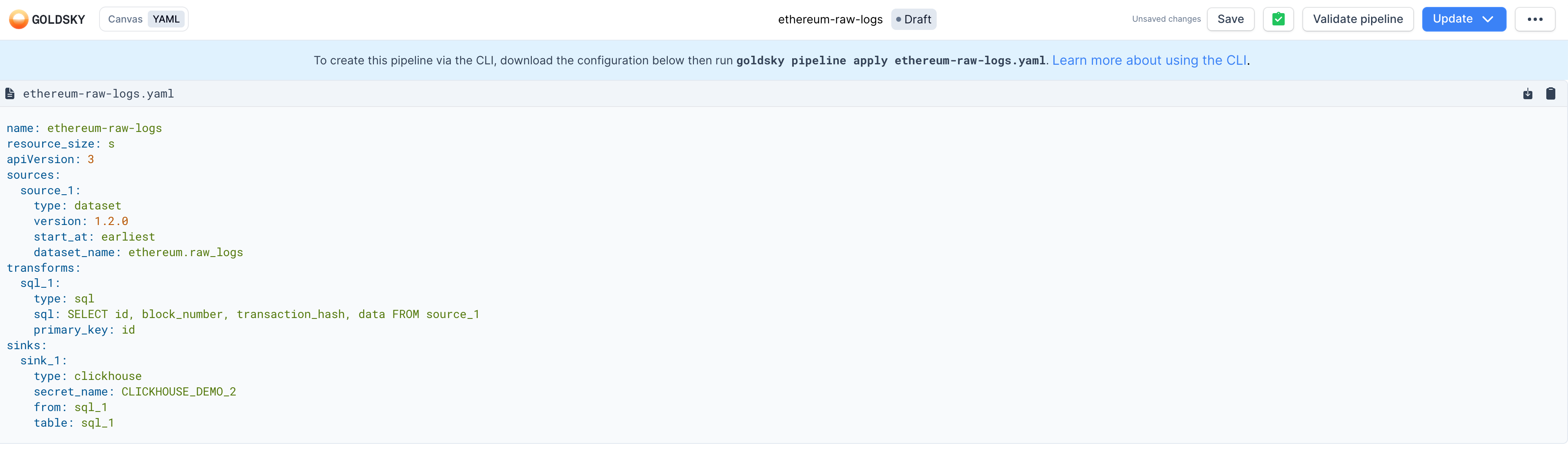
create the pipeline by dragging and dropping its components. You can at any time see the current configuration definition of the pipeline by switching the view to
YAMLon the top left corner. This is quite useful in cases where you’d like to version control your pipeline logic and/or automate its deployment via CI/CD using the CLI (as explained in next section)
- Pipeline components are interconnected via reference names: in our example, the source has a default reference name of
source_1; the transform (sql_1) reads fromsource_1in its SQL query; the sink (sink_1) reads the result from the transform (see itsInput sourcevalue) to finally emit the data into the destination. You can modify the reference names of every component of the pipeline on the canvas, just bear in mind the connecting role these names play.
Goldsky CLI
Install Goldsky's CLI and log in
Install Goldsky's CLI and log in
-
Install the Goldsky CLI:
For macOS/Linux:
For Windows:Windows users need to have Node.js and npm installed first. Download from nodejs.org if not already installed.
- Go to your Project Settings page and create an API key.
-
Back in your Goldsky CLI, log into your Project by running the command
goldsky loginand paste your API key. -
Now that you are logged in, run
goldskyto get started:
- Interactive
- Non-Interactive
Guided CLI experience
This is a simple and guided way to create pipelines via the CLI. Rungoldsky pipeline create <your-pipeline-name> in your terminal and follow the prompts.
In short, the CLI guides you through the following process:
- Select one or more source(s)
- Depending on the selected source(s), define transforms
- Configure one or more sink(s)
Custom Pipeline Configuration File
This is an advanced way to create a new pipeline. Instead of using the guided CLI experience (see above), you create the pipeline configuration on your own. A pipeline configuration is a YAML structure with the following top-level properties:sources and sinks are required with a minimum of one entry each. transforms is optional and an empty object ({}) can be used if no transforms are needed.
Full configuration details for Pipelines is available in the reference page.
As an example, see below a pipeline configuration which uses the Ethereum Raw Logs dataset as source, uses a transform to select specific data fields and sinks that data into a Postgres database whose connection details are stored within the A_POSTGRESQL_SECRET secret:
Example pipeline configuration
Example pipeline configuration
goldsky pipeline apply <your-pipeline-config-file-path> in your terminal to create a pipeline.
Once your pipeline is created, run goldsky pipeline start <your_pipeline_name> to start your pipeline.
Monitor a pipeline
When you create a new pipeline, the CLI automatically starts to monitor the status and outputs it in a table format. If you want to monitor an existing pipeline at a later time, use thegoldsky pipeline monitor <your-pipeline-name> CLI command. It refreshes every ten seconds and gives you insights into how your pipeline performs.
Or you may monitor in the Pipeline Dashboard page at https://app.goldsky.com/dashboard/pipelines/stream/<pipeline_name>/<version> where you can see the pipeline’s status, logs, metrics.