What you’ll need
- A Goldky account and the CLI installed
Install Goldsky's CLI and log in
Install Goldsky's CLI and log in
-
Install the Goldsky CLI:
For macOS/Linux:
For Windows:Windows users need to have Node.js and npm installed first. Download from nodejs.org if not already installed.
- Go to your Project Settings page and create an API key.
-
Back in your Goldsky CLI, log into your Project by running the command
goldsky loginand paste your API key. -
Now that you are logged in, run
goldskyto get started:
- A basic understanding of the Mirror product
- A destination sink to write your data to. In this example, we will use the PostgreSQL Sink
Introduction
Most of the Decentralized Exchanges these days are based entirely on the Uniswap protocol or have strong similarities with it.If you need a high level overview of how Uniswap works you can check out this reference page
Swap and PoolCreated events as they are arguably two of the most important events to track when wanting to make sense of trading activity in a DEX.
For this example implementation, we will choose the Raw Log Direct Indexing for the Base chain as the source of our pipeline but you could choose any other chain for which the Raw Log dataset if that is preferred.
Raw logs need to be decoded for us to be able to identify the events we want to track. For that purpose, we will use Decoding Transform Functions to dinamically fetch the ABIs of both UniswapV3Factory and UniswapV3Pool contracts from the Basescan API since they contain
the actual definition for the PoolCreated and Swap events.
It’s worth mentioning that Uniswap has different versions and it’s possible that some event definitions might differ. In this example we’ll focus on UniswapV3. Depending on the events you are interested in tracking you might want to refine this example accordingly but the principles explained will stay the same.
Pipeline Definition
base-dex-trades.yaml
If you copy and use this configuration file, make sure to update:
- Your
secretName. If you already created a secret, you can find it via the CLI commandgoldsky secret list. - The schema and table you want the data written to, by default it writes to
decoded_eventsschema.
Fast Scan Source
source
base_logs does and so we want to make use of it for this example dramatically.
We add as source filters the function signatures of the PoolCreated and Swap events:
PoolCreated (index_topic_1 address token0, index_topic_2 address token1, index_topic_3 uint24 fee, int24 tickSpacing, address pool)maps to0x783cca1c0412dd0d695e784568c96da2e9c22ff989357a2e8b1d9b2b4e6b7118Swap (index_topic_1 address sender, index_topic_2 address recipient, int256 amount0, int256 amount1, uint160 sqrtPriceX96, uint128 liquidity, int24 tick)maps to0xc42079f94a6350d7e6235f29174924f928cc2ac818eb64fed8004e115fbcca67
% to the end of each filter as topics contains more than just the function signature.
If the dataset we are using has the option for Quick Ingestion this filter will be pre-applied and it will speed up ingestion dramatically. Because not all datasets have this option enabled yet we’ll add some redundancy on the transform by adding extra filters on these events to make sure that we are targeting these two events regardless of this feature being available or not.
Next, there are 4 transforms in this pipeline definition which we’ll explain how they work. We’ll start from the top:
Decoding Transforms
Transform: factory_decoded
Transform: pool_decoded
PoolCreated and Swap events in the following transforms.
As explained in the Decoding Contract Events guide, we first make use of the _gs_fetch_abi function to get the ABIs from Basescan and pass it as first argument
to the function _gs_log_decode to decode its topics and data. We store the result in a decoded ROW which we unnest on the next transform.
Event Filtering Transforms
Transform: factory_clean
Transform: pool_clean
id: This is the Goldsky providedid, it is a string composed of the dataset name, block hash, and log index, which is unique per event, here’s an example:log_0x60eaf5a2ab37c73cf1f3bbd32fc17f2709953192b530d75aadc521111f476d6c_18decoded.event_params AS 'event_params': event_params is an array containing the params associated to each event. For instance, in the case of Swap events,event_params[1]is the sender. You could use this for further analysis in downstream processing.decoded.event_signature AS 'event_name': the decoder will output the event name as event_signature, excluding its arguments.WHERE decoded IS NOT NULL: to leave out potential null results from the decoderAND decoded.event_signature = 'PoolCreated': we use this value to filter only for ‘PoolCreated’ or ‘Swap’ events. As explained before, this filter will be redundant for datasets with Quick Ingestion enabled but we add it here in this example in case you would like to try out with a different dataset which doesn’t have that option enabled.
Mint you could easily add them to these queries; for example: WHERE decoded.event_signature IN ('Swap', 'Mint')
Both resulting datasets will be used as sources to two different tables at our sink: decoded_events.poolcreated & decoded_events.swaps
Deploying the pipeline
Assuming we are using the same filename for the pipeline configuration as in this example we can deploy this pipeline with the CLI pipeline create command:goldsky pipeline apply base-dex-trades.yaml --status ACTIVE
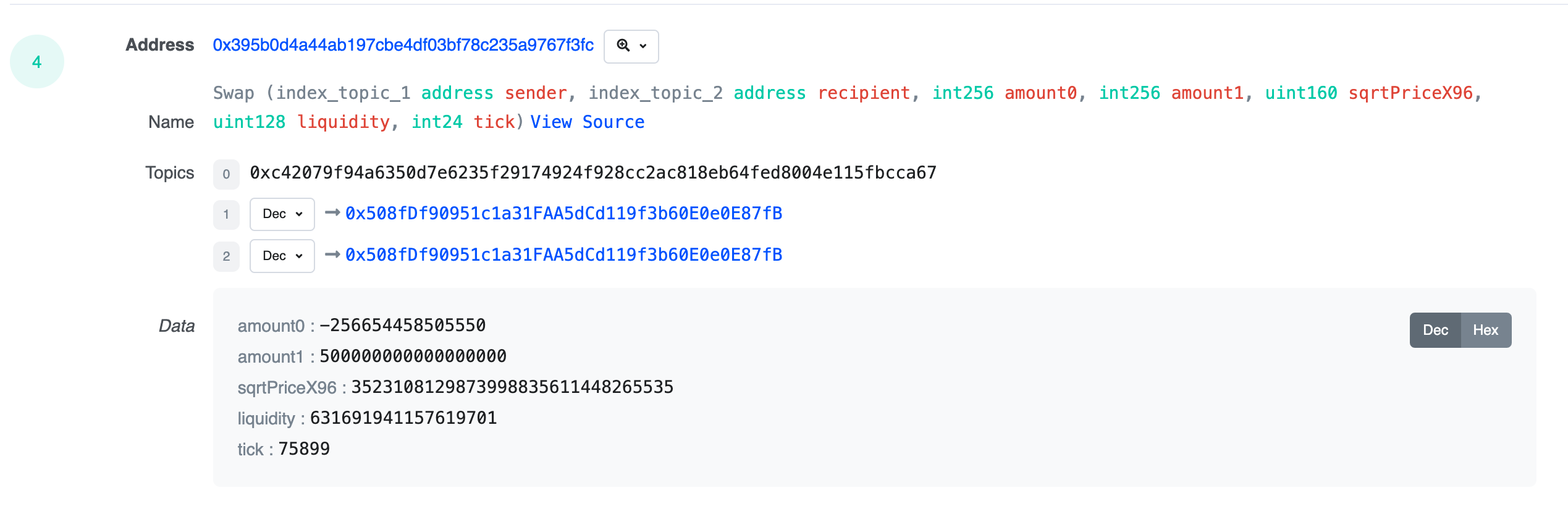
Here’s an example Swap record from our sink:
We can see that it corresponds to the Swap event of this transaction: